This is part 2 rambling in this series related to trade-offs when deciding between solution options.
In one of my client assignments where I was a
lead architect for their data platform, on an occasion there was a jour-fixe
session to discuss together as a team involving client data strategists, data
owners, product owners and project managers,
there was a requirement to handle
streaming data which comes in real-time from their trading systems to develop a
real-time ingestion, analytics and reporting to help traders, front-office team
to get a view of their positions on any given time of the day.
(We take a diversion here to set some
context)
Context setting:
Clients had license for the ETL tool Talend,
which was hosted in on-premises. Talend cloud was still getting matured. Hence,
clients had already taken a decision to use Talend for any data integration,
transformation requirements to have one consistent tooling framework and to
leverage cost-benefit ratio as they were already heavily invested into it.
It’s like since I have bought this expensive
medicine for cough, I should only use this medicine for any health ailments. :)
Talend on-premises is a great tool it
can copy / transform millions of rows of data from any data source in few
seconds.
Azure data factory was not that mature in
those days (year 2018) in terms of performance and features.
Talend allows us to go beyond standard
built-in transformation options and lets us write custom Java code deploying it
as jar files to enable us to do advanced rule-based transformations.
On the hindsight, Talend on-premises did not
have a great DevOps support.
Every time we want to re-create the Talend
job in a higher environment from dev, we had to develop manually or manually
export job and import it.
Also, Talend on-premises was great for batch
processing but does not farewell in real-time.
For our use-case, there was already a
prototype in place for the real-time reporting solution which involved a
relatively longer route for data to reach from source to destination. Prototype
version's architecture is as follows:
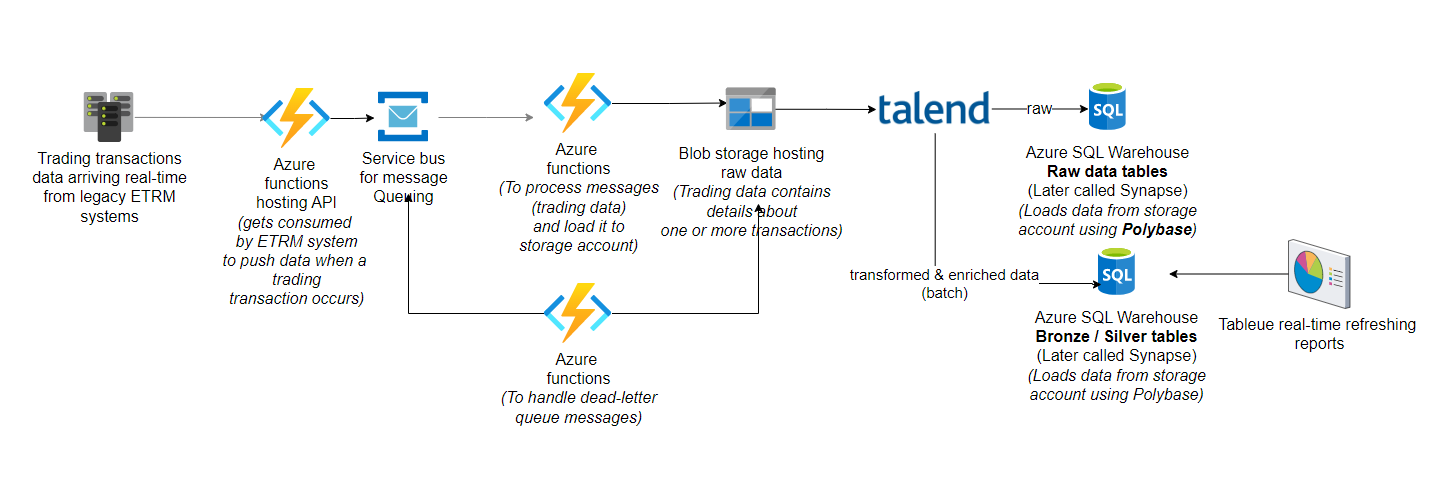
First version of real-time reporting solution
with a relatively longer lead-time for a streaming data to reflect in a report.
Though this architecture was delivering the
purpose, there was about 10 minutes lag in data reaching from the ETRM system
to the target tables in aggregated format for reporting purpose.
There were too many azure functions and most
times, there were issues with messages not being processed in queue.
Also, there were issue of raw data coming in
with more than few megabytes on cases where the ETRM systems sends burst of
many transactions at once causing messages size to increase leading to failure
of processing due to limitations of around message size.
Lead to next blog:
This particular problem is wide-faced with
cloud messaging services, in a later blog we can look at how to resolve this
issue using claim-check cloud design pattern (Claim-Check
pattern - Azure Architecture Center | Microsoft Learn)
(Coming back to the previous lane after
diversion)
In the Jour fixe session, we were discussing
ways to reduce this 10-minute lag time to get to near real-time to few seconds
or about a minute.
For traders, as you know every clock tick is
a million lost or gained. If they get to see their positions (in an aggregated
or detailed view) much in advance, it will help them to adjust / plan their
future transactions based on past transactions profit / loss. It is much more
to that but my domain knowledge in this case is limited, to which i still
regret not learning more on this area.
I proposed Azure event hub to avoid these
multiple hops and to increase streaming and scalability.
It was a healthy debate with many client
colleagues challenging event hub and some proposed Kafka on-premises.
Talend on-premises was already eating up some
of the time due to latency between cloud and on-premises, introducing Kafka
on-premises would only increase the lag time further.
Finally, the meeting ended with an action for
me to do a quick POC using event hub. With help of a developer (who is
passionate to technology, i must say) in the team, we created a modified
implementation which looked like this one below reducing function apps,
replacing service bus with event hub.

Improved version with Azure event hub leading to less lag in streaming data reaching the destination store and availability in report.
With default scaling level, event hub was
trying to catchup with incoming real-time streaming messages. With some
capacity planning, we increased partition size and throughput which then helped
us to massively increase the messaging arrival and processing speed. Event hub
has in-build retry mechanism to resend failed message.
Later we migrated from Azure SQL warehouse to
Snowflake cloud warehouse adapting to clients Data strategy, this migration
effort alone deserves another blog.
Takeaway: we discussed choosing between messaging
services like service bus, topics, queues over PaaS streaming services like
Azure event hub based on the use-case requirements. Again, it is not one-size
fits for all. Each solution has its own requirement, and it deserves the
services that justifies making it an optimal solution.
P:S.
Of course, the devil is in details. There are
many intricacies with respect to business logic. Like for example, if a trading
transaction is done and it has reached the data warehouse but there was a
cancellation transaction done at later point. In this case, both the initial
and cancellation transaction must be consolidated and negated in order to
maintain consistent and data correctness. There are many such cases which are
not discussed here considering blog scope.











